Posts on the Topic Similarity

ROUGE is a key metric in plagiarism detection that quantifies text similarity through n-gram analysis, helping identify copying and paraphrasing while having some limitations. It measures lexical overlap but may miss semantic meaning, making it beneficial to use alongside other...
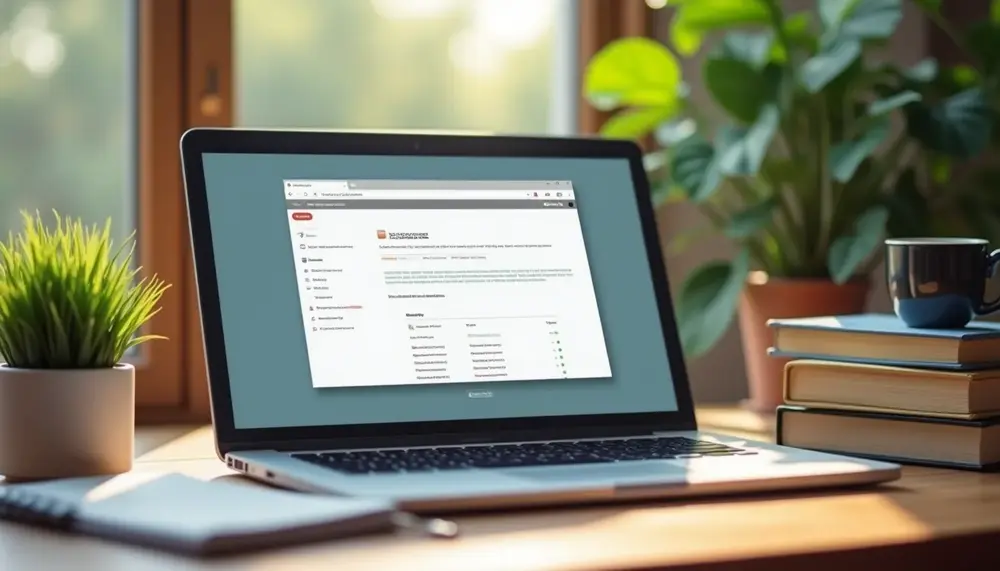
The Oxsico text similarity report provides an overview of your work's originality through a similarity score, number of matches, document type, and source credibility. Analyzing highlighted sections and the source list helps identify areas needing improvement to ensure academic integrity....

Understanding text similarity datasets is essential for NLP research, particularly in analyzing emotional and thematic parallels in poetry across languages. These datasets enhance semantic analysis, enabling deeper insights into the nuances of poetic expression....

A plagiarism detection algorithm effectively combines techniques like Levenshtein distance and common word analysis to identify text similarities, distinguishing between original and revised content. By preprocessing texts and setting similarity thresholds, it promotes academic integrity by accurately flagging potential plagiarism...

Jaccard Similarity measures the similarity between two sets by comparing their intersection and union, useful in various fields like text analysis and recommendation systems. It can be easily calculated in Python using set operations to derive a score ranging from...

UWE Bristol emphasizes academic integrity by using SafeAssign, a tool that helps students check for plagiarism in their work before final submission. Understanding how to use this tool and the importance of proper citation is crucial for maintaining originality and...

Hugging Face is a leading platform for text similarity models in NLP, offering pre-trained models and community support that enhance innovation and accessibility. Its tools enable nuanced sentence comparisons essential for applications like information retrieval....

Small SEO Tools offers a free and user-friendly Plagiarism Checker that efficiently detects potential plagiarism, supports multiple languages, and includes additional writing tools like grammar checking and paraphrasing. Its comprehensive database ensures quick analysis while promoting originality in content creation...

Text Similarity APIs utilize advanced NLP algorithms to evaluate the similarity between texts, enhancing content creation by ensuring originality and improving SEO performance. They streamline processes like plagiarism detection and content curation, making them essential tools for modern digital marketing...

String similarity algorithms, like Levenshtein distance and SimilarText, measure how closely two strings resemble each other for applications in text processing and data deduplication. While Levenshtein focuses on edit distances, SimilarText evaluates percentage similarities based on matching sequences, each with...

Optimizing text similarity functions involves selecting appropriate metrics, preprocessing data, using advanced embeddings, and continuously evaluating performance while avoiding common pitfalls. Future trends include multimodal integration, personalized systems, real-time analysis, explainable AI, and addressing ethical concerns....

The Levenshtein Distance is a string metric that measures text similarity by counting the minimum edits needed to transform one string into another, with applications in spell checking and plagiarism detection. Its algorithm uses dynamic programming to efficiently calculate edit...

Text Similarity Babbage 001 enhances plagiarism detection by utilizing advanced algorithms for semantic analysis, enabling quick and accurate identification of similarities in large text volumes. Its ability to adapt and learn continuously makes it a reliable tool for maintaining academic...

Learn how algorithmic detection works, why it flags content, and how to stay compliant. Expert breakdown with real examples and actionable tips....

Text similarity is vital in fields like linguistics and data mining, aiding tasks such as plagiarism detection and content recommendation through various methodologies. Key tools for analysis include Turnitin, Grammarly, and Semantic Scholar, each offering unique features tailored to different...

The quanteda package offers essential tools for text analysis, particularly through its functions textstat_simil and textstat_dist, which compute similarities and distances between documents using sparse Document-Feature Matrices. Mastering these methods enhances researchers' ability to conduct nuanced analyses while ensuring accurate...

Text comparison algorithms are essential for data analysis and natural language processing, enhancing applications like translation services, plagiarism detection, and version control. Understanding their functionalities allows organizations to improve data quality and optimize processes in a competitive landscape....

Researchers utilize various text similarity measures, such as Cosine Similarity and TF-IDF, to evaluate textual relationships in fields like NLP and machine learning. Understanding these algorithms is essential for accurate analysis and insights from textual data....

Understanding plagiarism in academic writing is essential for maintaining integrity, with a similarity index above 15-20% often raising concerns; context and proper citation are key. Familiarizing oneself with institutional guidelines helps avoid unintentional violations and promotes originality....

Text similarity is vital in sentiment analysis, enhancing emotion detection and opinion mining while facing challenges like language ambiguity and data quality issues. Its effective use can drive better customer insights and strategic decisions....

Understanding text similarity in Scikit-Learn involves using metrics like Cosine and Jaccard similarity to compare documents, particularly Java classes, through effective vectorization and preprocessing techniques. Setting up the environment includes installing libraries, organizing project structure, and preparing data for accurate...

Text similarity is essential across various fields, enhancing tasks like NLP, plagiarism detection, recommendation systems, and search engines by improving understanding and relevance. Key techniques for measuring text similarity include cosine similarity, Jaccard index, TF-IDF, Word2Vec, and Levenshtein distance....

Description-based text similarity enhances research by focusing on semantic content for improved information retrieval and model training, utilizing advanced language models to generate relevant results....

Text similarity visualization uses advanced NLP techniques to graphically represent textual similarities, aiding in plagiarism detection and enhancing understanding of content relationships. It transforms complex data into interactive formats like heat maps, allowing users to identify patterns while fostering academic...

Training models for semantic textual similarity involves fine-tuning pre-trained models with well-structured datasets, appropriate loss functions, and hyperparameter optimization to enhance performance. Techniques like distributed training further improve efficiency by leveraging multiple devices or machines....
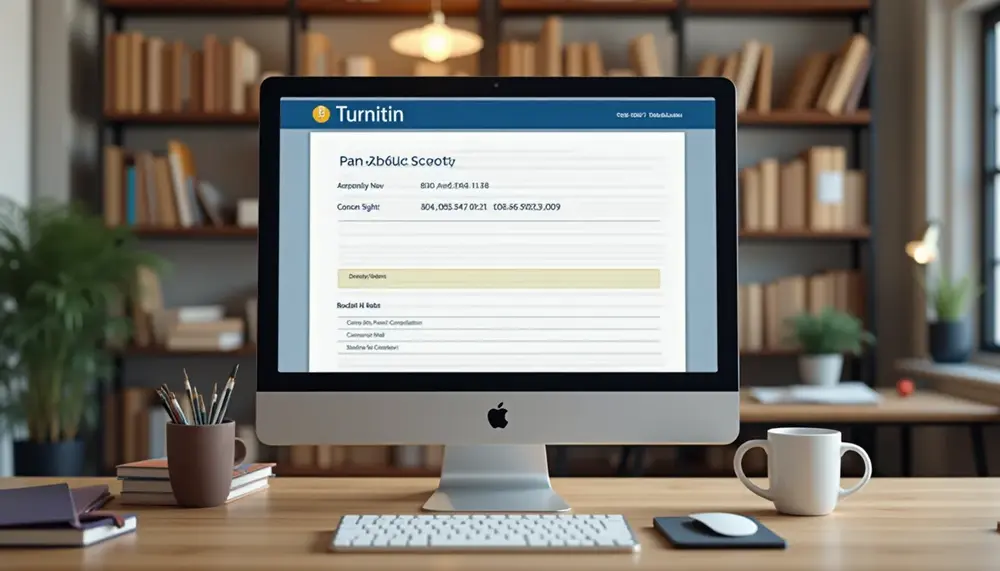
To check your plagiarism percentage on Turnitin, log in to your account, select the relevant class and assignment, then click on the Similarity Score to view the report. Be aware that a high score doesn't necessarily indicate plagiarism; it highlights...

Data preparation is essential for effective Word2Vec usage, involving text collection, cleaning, tokenization, and model training with careful hyperparameter selection. While it captures semantic relationships well and supports various applications, it requires significant preprocessing and may struggle with out-of-vocabulary words....

The `ai.similarity` function in PySpark computes semantic similarity between text expressions efficiently with minimal code, leveraging Spark's capabilities for large datasets. It offers flexible comparisons and customizable outputs while being user-friendly for data scientists and analysts....

This article introduces text similarity in Python, covering key metrics like cosine and Jaccard similarity, along with practical implementations using libraries such as scikit-learn. It emphasizes the importance of selecting appropriate methods for various applications in natural language processing....

Text similarity vectors are essential for analyzing natural language, enabling AI applications like recommendation systems and semantic search by measuring textual similarities through various techniques. Understanding these vectors enhances the effectiveness of machine learning models in interpreting human language meaningfully....